

Installing WhisperAI from OpenAI... for FREE.
Or: Exploring Technologies for the VocalCue.com Teleprompter Project.

Thank you for reading this post.
My name is Brian and I'm a developer from New Zealand. I've been interested in computers since the early 1990s. My first language was QBASIC. (Things have changed since the days of MS-DOS.)
I am the managing director of a one-man startup called Digital Core (NZ) Limited. I have accepted the "12 Startups in 12 Months" challenge so that DigitalCore will have income-generating products by April 2024.
This blog will follow the "12 Startups" project during its design, development, and deployment, cover the Agile principles and the DevOps philosophy that is used by the "12 Startups" project, and delve into the world of AI, machine learning, deep learning, prompt engineering, and large language models.
I hope you enjoyed this post and, if you did, I encourage you to explore some others I've written. And remember: The best technologies bring people together.
TL;DR.
This post guides me through the process of installing WhisperAI from OpenAI for FREE. It covers prerequisites like a Debian-based Linux distro and Miniconda, steps to update my system, and installing essential technologies such as FFmpeg, CUDA Toolkit, PyTorch, and Whisper. It also covers how to set up a Miniconda environment, creating directories, and running Whisper for speech recognition and translation. A future post will further explore how to use Python and Whisper together.
Attributions:
https://docs.anaconda.com/free/miniconda/index.html↗,
https://openai.com/index/whisper/↗,
An Introduction.
One of the earliest, and most important, AI projects for DigitalCore to complete is the VocalCue.com app. Whisper may become a lynch-pin technology for the success of the VocalCue project.
The purpose of this post is to install Whisper, and explore its' basic functionality.
Please note that VocalCue.com is a working title and may be replaced on launch.
The Big Picture.
Whisper is an open-source project from OpenAI and is available to the public under the MIT license. If I decide to use Whisper as part of my VocalCue teleprompter project, then I will also open-source my code under the same license. This post is all about installing the Whisper tool, as well as three other supporting technologies.
Prerequisites.
A Debian-based Linux distro (I use Ubuntu),
Updating my Base System.
- From the (base) terminal, I update my (base) system:
sudo apt clean && \
sudo apt update && \
sudo apt dist-upgrade -y && \
sudo apt --fix-broken install && \
sudo apt autoclean && \
sudo apt autoremove -y
NOTE: The Ollama LLM manager is already installed on my (base) system.
What is FFmpeg?
FFmpeg is a top multimedia tool that can decode, encode, transcode, mux, demux, stream, filter, and play almost any format created by humans or machines. It supports both old and new formats, whether made by a standards group, the community, or a company. FFmpeg is also very portable: it can be compiled, run, and tested on Linux, Mac OS X, Windows, BSDs, Solaris, and more, across different build environments, machine types, and setups.
1 of 4: Installing FFmpeg.
- I check to see which version of FFmpeg is installed:
ffmpeg -v
NOTE: FFmpeg will need installing if it is not already on my system.
- I install FFmpeg, if required, into my (base) environment:
sudo apt update && sudo apt install ffmpeg
What is CUDA?
CUDA is a parallel computing platform and programming model created by NVIDIA. It has been downloaded over 20 million times and helps developers speed up their applications using GPU accelerators. CUDA is used in many fields, not just high-performance computing and research. For example, pharmaceutical companies use CUDA to find new treatments, cars use it to improve self-driving, and stores use it to analyse customer data for recommendations and ads.
Some people think CUDA, launched in 2006, is just a programming language or an API. But with over 150 CUDA-based libraries, SDKs, and tools, it's much more than that. NVIDIA keeps innovating, and thousands of GPU-accelerated applications use the NVIDIA CUDA platform. CUDAs flexibility and programmability make it the top choice for developing new deep learning and parallel computing algorithms.
CUDA also helps developers easily use the latest GPU features, like those in the NVIDIA Ampere GPU architecture.
https://blogs.nvidia.com/blog/what-is-cuda-2/ ↗.
2 of 4: Installing the CUDA Toolkit.
NOTE: This section only applies to PCs that use NVIDIA GPUs. Other graphics processors, i.e. AMD GPUs, will need a different process. I replaced my SAPPHIRE Radeon Nitro+ RX-580 for an NVIDIA RTX-3060 with 12GB of VRAM.)
- The following command is available from the NVIDIA website:
https://developer.nvidia.com/cuda-downloads↗.
NOTE: I use the map at the above website to define the following command.
- I install the NVIDIA CUDA Toolkit into my (base) environment:
sudo apt install -y nvidia-cuda-toolkit
- I check my installed CUDA version:
nvcc --version
What is Anaconda and Miniconda?
Python projects can run in virtual environments. These isolated spaces are used to manage project dependencies. Different versions of the same package can run in different environments while avoiding version conflicts.
venv is a built-in Python 3.3+ module that runs virtual environments. Anaconda is a Python and R distribution for scientific computing that includes the conda package manager. Miniconda is a small, free, bootstrap version of Anaconda that also includes the conda package manager, Python, and other packages that are required or useful (like pip and zlib).
https://docs.anaconda.com/free/miniconda/index.html↗, and
https://solodev.app/installing-miniconda.
I ensure Miniconda is installed (conda -V) before continuing with this post.
Creating a Miniconda Environment.
- I use the
condacommand to display alistof Minicondaenvironments:
conda env list
- I use
condatocreate, andactivate, a new environment named (-n) (Whisper):
conda create -n Whisper python=3.10 -y && conda activate Whisper
NOTE: This command creates the (Whisper) environment, then activates the (Whisper) environment.
Creating the Whisper Home Directory.
NOTE: I will now define the home directory in the environment directory.
- I create the
Whisperhome directory:
mkdir ~/Whisper
- I make new directories within the (Whisper) environment:
mkdir -p ~/miniconda3/envs/Whisper/etc/conda/activate.d
- I use the Nano text editor to create the
set_working_directory.shshell script:
sudo nano ~/miniconda3/envs/Whisper/etc/conda/activate.d/set_working_directory.sh
- I copy the following, paste (CTRL + SHIFT + V) it to the
set_working_directory.shscript, save (CTRL + S) the changes, and exit (CTRL + X) Nano:
cd ~/Whisper
- I activate the (base) environment:
conda activate
- I activate the (Whisper) environment:
conda activate Whisper
NOTE: I should now, by default, be in the
~/Whisperhome directory.
What is PyTorch?
PyTorch is an open-source deep learning framework known for its flexibility and ease of use. It works well with Python, a popular language among machine learning developers and data scientists. PyTorch is a complete framework for building deep learning models, which are often used in tasks like image recognition and language processing. Since it is written in Python, most machine learning developers find it easy to learn and use. PyTorch was created by developers at Facebook AI Research and other labs. It combines fast and flexible GPU-accelerated back-end libraries from Torch.ch with an easy-to-use Python frontend. This makes it great for quick prototyping, readable code, and supporting many types of deep learning models. PyTorch allows AI engineers to use a familiar programming style while still creating graphs. It was open-sourced in 2017, and its' Python base has made it popular with machine learning developers.
3 of 4: Installing PyTorch.
- The following command is available from the PyTorch website:
https://pytorch.org/get-started/locally/↗.
NOTE: I use the map at the above website to define the following command.
- I install PyTorch in the (Whisper) environment:
pip3 install torch torchvision torchaudio \
--index-url https://download.pytorch.org/whl/cu118
What is WhisperAI?
From the GitHub page↗:
Whisper is a speech recognition model. It is trained on a large set of audio types and can perform multiple tasks like recognizing different languages, transcribing spoken text, and translating multiple languages to English.
4 of 4: Installing Whisper AI.
- I use the pip command to install Whisper into the (Whisper) environment:
pip install -U openai-whisper
NOTE: The
-Uflag means upgrade, if Whisper is already installed.
Running WhisperAI.
I place an audio file, called test.wav, into the Whisper directory.
I run the following command:
whisper test1.wav
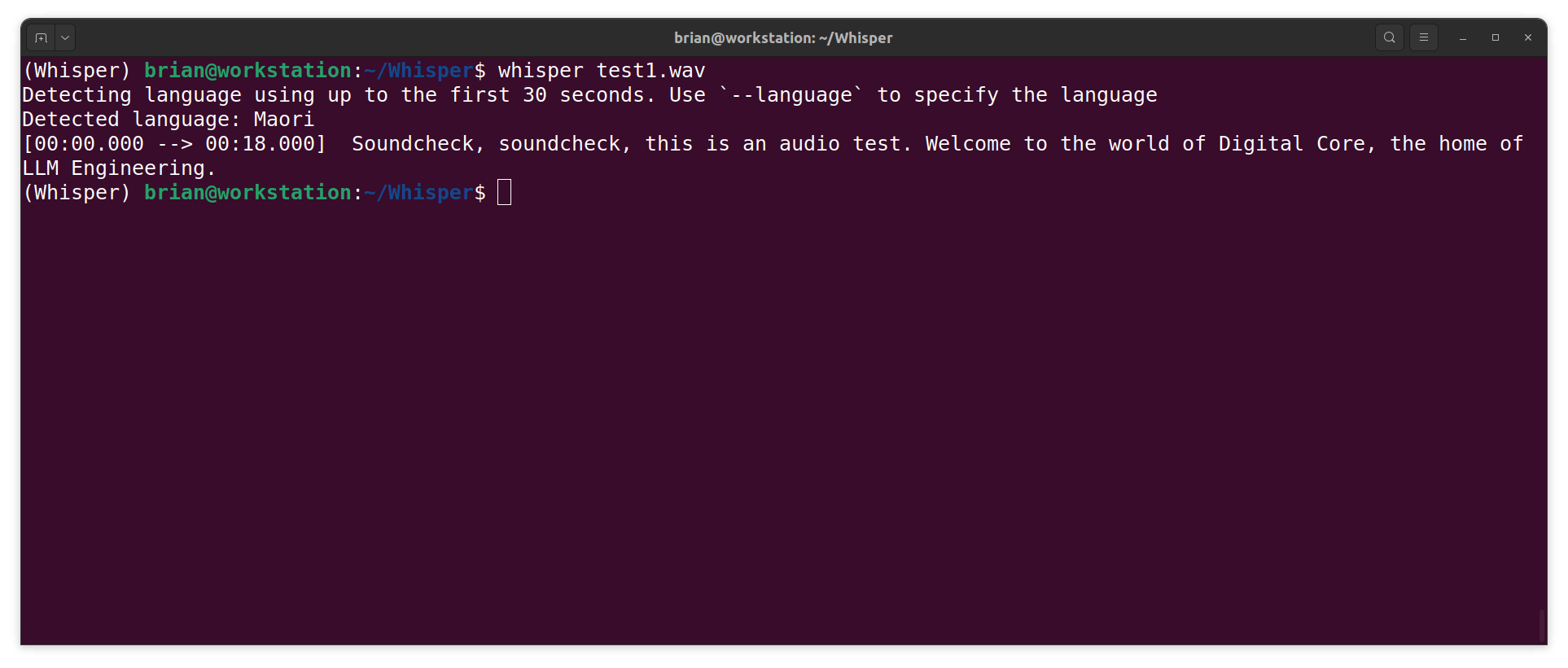
NOTE: I didn't set the
--languageflag. Whisper decided I was speaking Maori. Actually, the recording is of a Maori speaking. The model may have detected my accent. Or not. Who knows?
- Next, I test Whisper to see if FFmpeg can provide it with the original MP4 file:
whisper test2.mp4
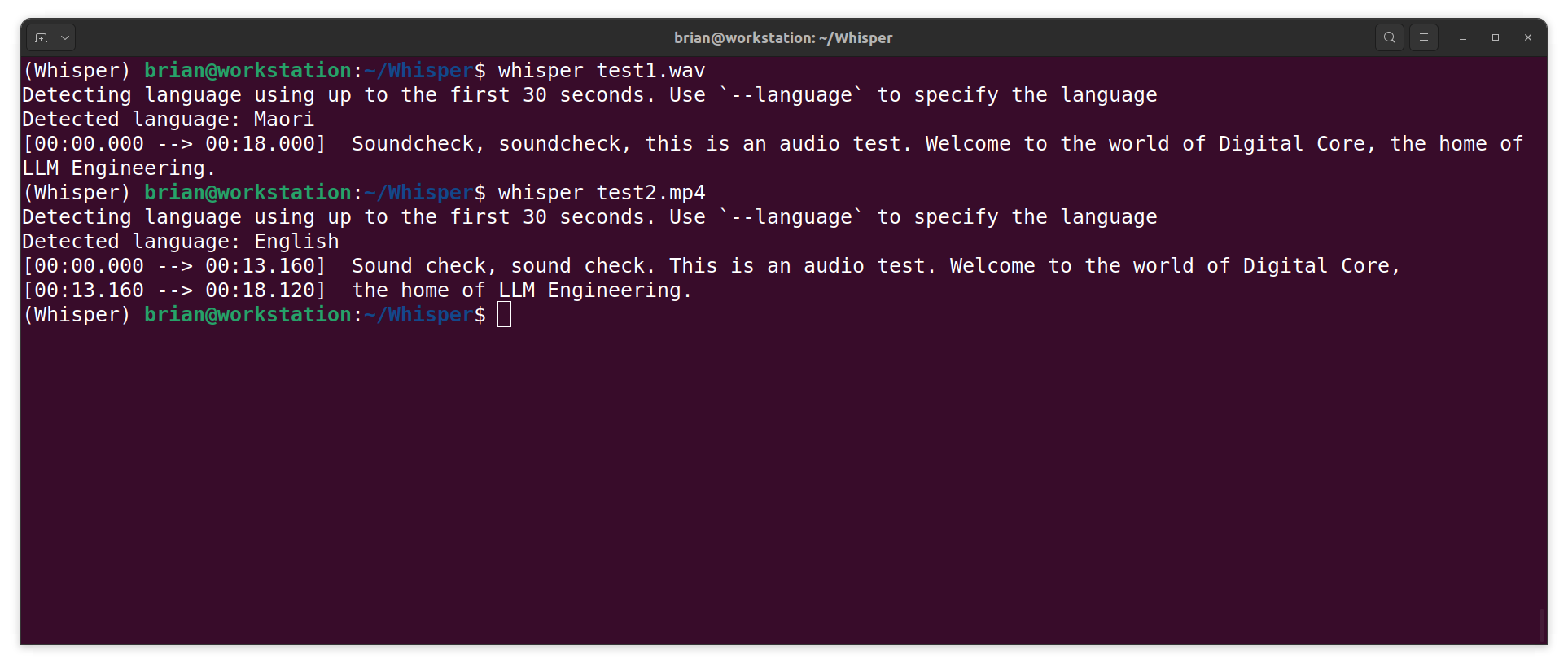
NOTE: The MP4 test worked. Nice.
- Each time Whisper runs, it generates a number of files:
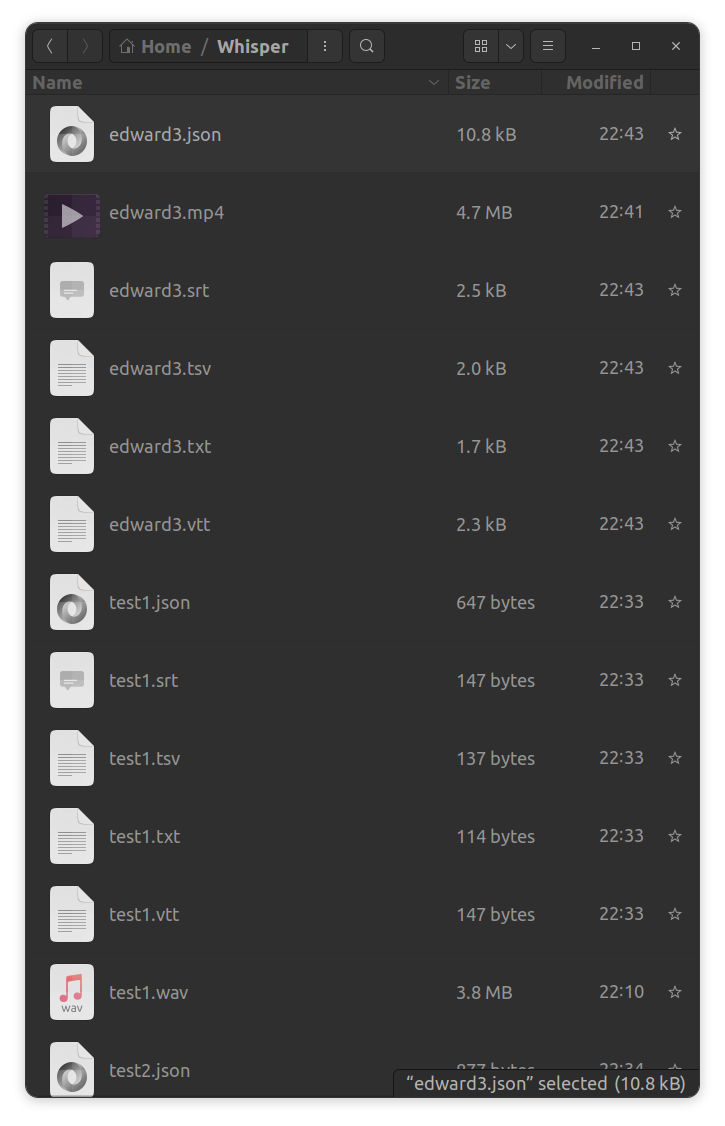
NOTE: Whisper can transcribe multiple files, where each file name is separated by a space.
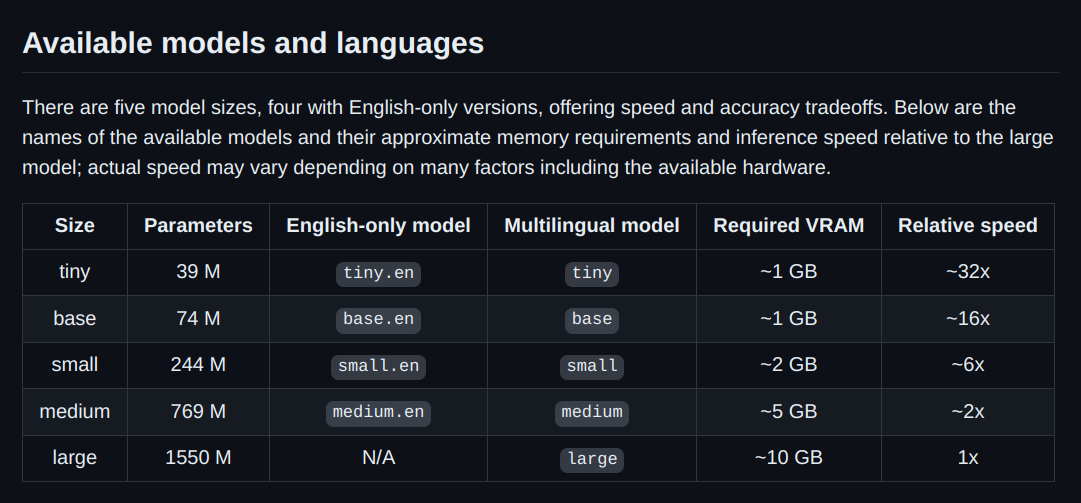
Whisper has 5 Model Sizes.
NOTE: By default, Whisper uses the small model but there are other models, too.
- This time, I test Whisper on a bit of Shakespeare using a different model:
whisper richard3.mp4 --model medium
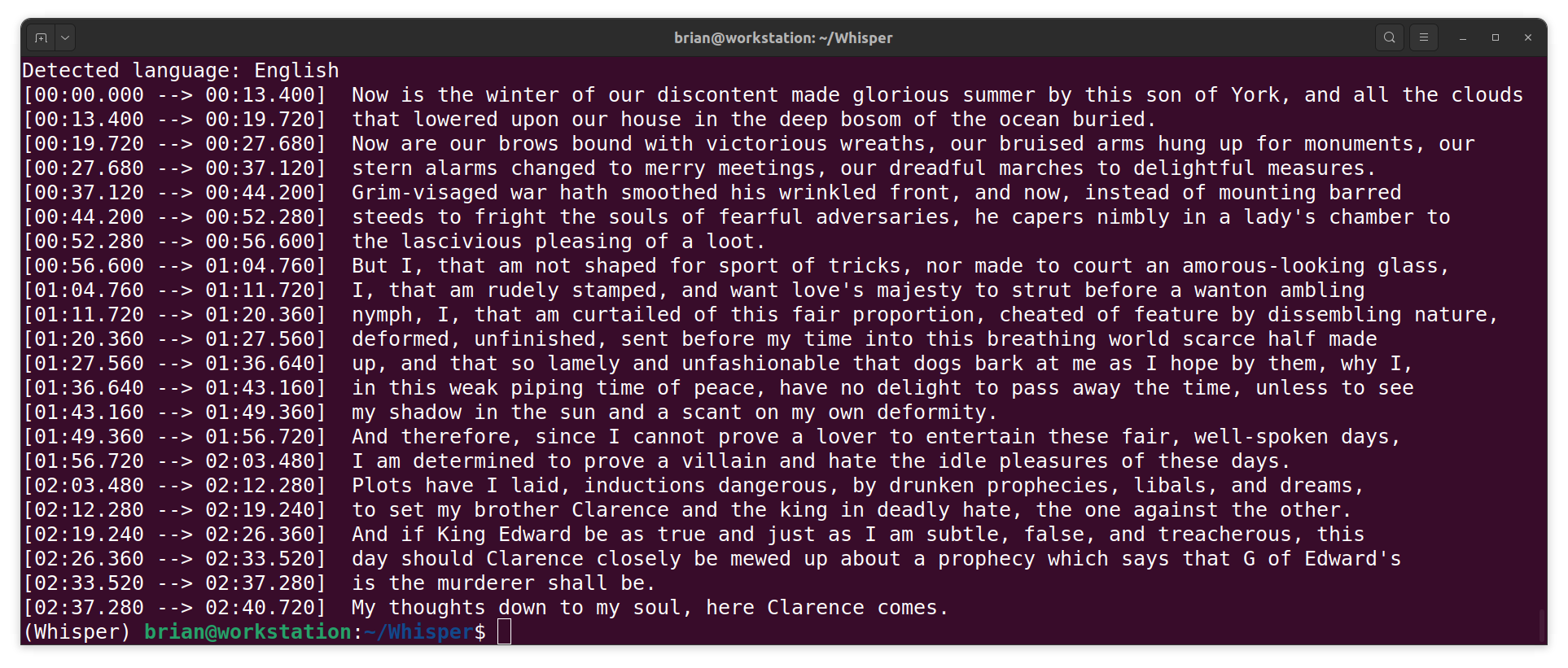
NOTE: Whisper got most of it, but my recording wasn't great. (I didn't warm up.)
Transcribing and Translating Other Languages.
- I can use the
--languageflag for recordings in other languages, instead of forcing Whisper to use auto-detect feature within the first 30-seconds:
whisper french.wav --language French
- I can also translate the audio thanks to the
--taskflag:
whisper french.wav --language French --task translate
NOTE: Translate only works from other languages to English. The other languages include (as per the
--helpflag) Afrikaans, Albanian, Amharic, Arabic, Armenian, Assamese, Azerbaijani, Bashkir, Basque, Belarusian, Bengali, Bosnian, Breton, Bulgarian, Burmese, Cantonese, Castilian, Catalan, Chinese, Croatian, Czech, Danish, Dutch, English, Estonian, Faroese, Finnish, Flemish, French, Galician, Georgian, German, Greek, Gujarati, Haitian, Haitian Creole, Hausa, Hawaiian, Hebrew, Hindi, Hungarian, Icelandic, Indonesian, Italian, Japanese, Javanese, Kannada, Kazakh, Khmer, Korean, Lao, Latin, Latvian, Letzeburgesch, Lingala, Lithuanian, Luxembourgish, Macedonian, Malagasy, Malay, Malayalam, Maltese, Mandarin, Maori, Marathi, Moldavian, Moldovan, Mongolian, Myanmar, Nepali, Norwegian, Nynorsk, Occitan, Panjabi, Pashto, Persian, Polish, Portuguese, Punjabi, Pushto, Romanian, Russian, Sanskrit, Serbian, Shona, Sindhi, Sinhala, Sinhalese, Slovak, Slovenian, Somali, Spanish, Sundanese, Swahili, Swedish, Tagalog, Tajik, Tamil, Tatar, Telugu, Thai, Tibetan, Turkish, Turkmen, Ukrainian, Urdu, Uzbek, Valencian, Vietnamese, Welsh, Yiddish, and Yoruba.Whispers' performance varies widely depending on the language. Translations are not perfect, but they are good enough to be understood.
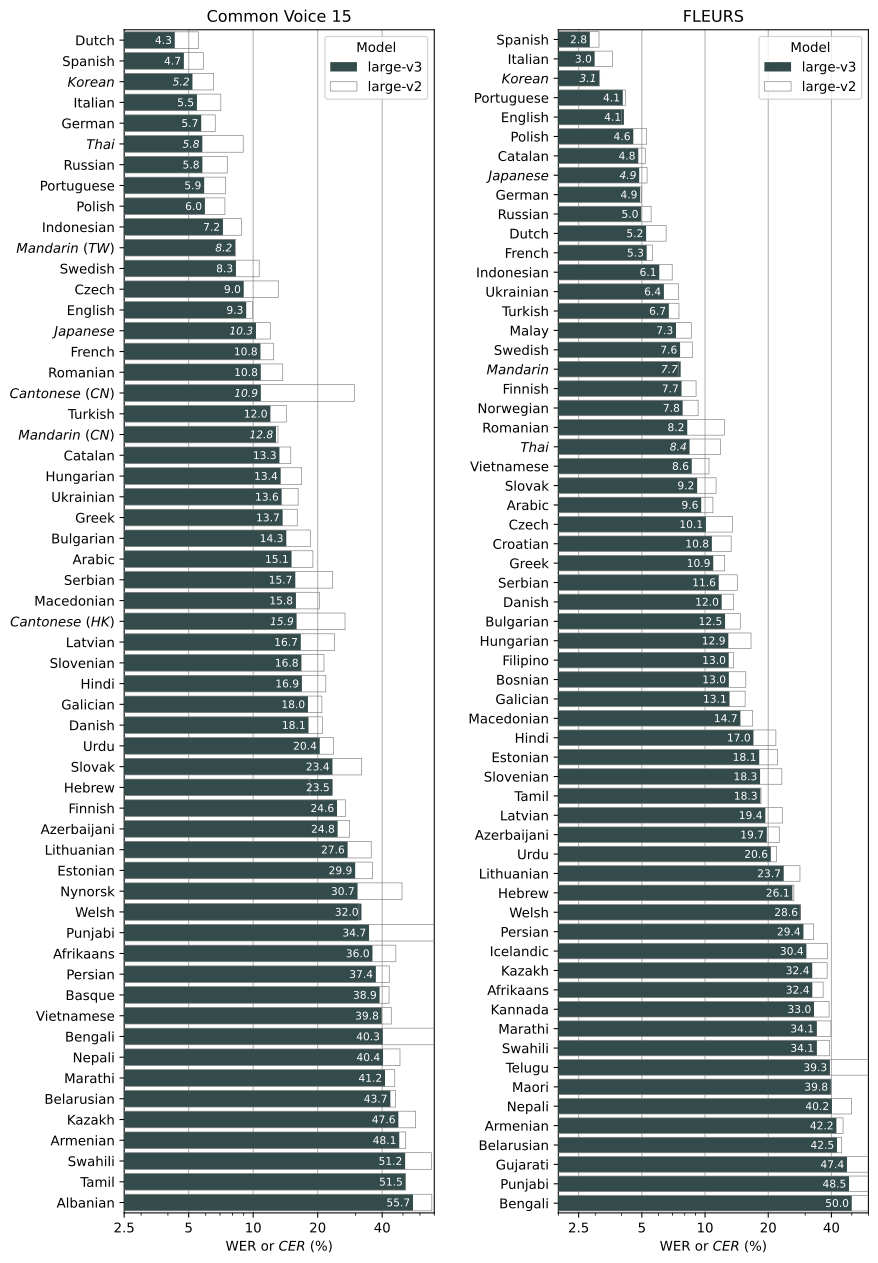
From the GitHub repo: The image below shows that a lower number means better performance. It is a breakdown of large-v3 and large-v2 models by language, using WERs (word error rates) or CER (character error rates, shown in Italic) evaluated on the Common Voice 15 and Fleurs datasets.
The Next Step.
In a follow-up post, I will look at using Python to manipulate Whisper. Python is an easy-to-learn programming language that is popular with AI scientists and engineers.
The Results.
Installing WhisperAI from OpenAI is a straightforward process if I follow these steps and prerequisites. By ensuring I have the right environment, tools like FFmpeg, CUDA Toolkit, PyTorch, and Whisper itself, I can effectively set up and utilize this powerful speech recognition model. Whispers' ability to transcribe text and translate audio to English, from multiple languages, makes it a versatile tool for numerous applications. In a future post, I will explore more advanced usage and customization by using Python, opening up even more possibilities for integrating Whisper into my projects.
In Conclusion.
I have unlocked the power of FREE speech recognition with Whisper.
I can install, and use, Whisper from OpenAI for FREE. Yes, you heard that right! Whisper, an open-source speech recognition model, is now available for everyone under the MIT license. I dived into how to set it up and start using it today.
Prerequisites:
A Debian-based Linux distro (I use Ubuntu)
Miniconda
Steps to Get Started:
I updated my (base) environment:
- I make sure my system is up to date and stable.
I installed essential technologies:
FFmpeg: I checked for FFmpeg, and installed if it was not available.
CUDA Toolkit: The CUDA toolkit is used to access NVIDIA GPUs.
PyTorch: I installed PyTorch using the command from its' website.
WhisperAI: I used pip to install Whisper into a virtual environment.
Set Up Miniconda Environment:
- I created and activated a new environment for Whisper.
Created the Whisper Home Directory:
- I set up directories and scripts to streamline my workflow.
Running WhisperAI:
I placed audio files into the Whisper directory and ran the Whisper command.
Whisper can transcribe, and translate multiple languages to English, making it a versatile tool for numerous applications.
Whisper Models:
- Whisper comes with 5 different model sizes. I chose the ones that fit my needs.
Next Steps:
- In a future post, I will explore how to manipulate Whisper using Python, unlocking more flexibility for creating my own projects.
Results:
- Setting up Whisper is straightforward if I follow these steps and prerequisites. With tools like FFmpeg, CUDA Toolkit, PyTorch, and Whisper, I can effectively utilize this powerful speech recognition model.
Are you excited to try Whisper in your own projects? What other AI tools are you interested in exploring? Let's discuss in the comments below!
Until next time: Be safe, be kind, be awesome.
#WhisperAI #OpenAI #SpeechRecognition #Transcription #LanguageTranslation #AI #Python #PyTorch #NVIDIA #CUDA #FFmpeg #AItools #AIresearch #MachineLearning #DeepLearning #Miniconda #TechInnovation #FreeTools #OpenSource #TechTutorial #Ubuntu #Linux #Programming
1/ 🚀 Unlock the power of FREE speech recognition with WhisperAI from OpenAI! Dive into this step-by-step guide to install and explore Whisper for your projects. Ready to get started?
2/ First, ensure you have a Debian-based Linux distro (I use Ubuntu) and Miniconda installed. These are essential prerequisites for setting up WhisperAI.
3/ Update your base system to ensure it’s stable and up-to-date. This is a crucial step before installing any new software or dependencies.
4/ Whisper requires four key technologies: FFmpeg, CUDA Toolkit, PyTorch, and Whisper itself. I’ll walk you through installing each one.
5/ Check if FFmpeg is installed. If not, install it in your base environment. FFmpeg is crucial for handling audio files.
6/ If you have an NVIDIA GPU, install the CUDA Toolkit. This toolkit allows Whisper to leverage the power of your GPU for faster processing.
7/ Next, install PyTorch. This powerful deep learning framework is essential for running Whisper. Follow the command from the PyTorch website.
8/ With PyTorch installed, use pip to install Whisper into a new virtual environment created with Miniconda. This keeps dependencies isolated.
9/ Create and activate a new Miniconda environment specifically for Whisper. This keeps your Whisper setup organized and separate from other projects.
10/ Set up the Whisper home directory within your new environment. Create necessary directories and a script to streamline your workflow.
11/ Place your audio files into the Whisper directory and run the Whisper command. Whisper can transcribe and translate audio, making it incredibly versatile.
12/ Whisper offers five different model sizes. Choose the one that fits your needs for accuracy and performance. Experiment to find the best fit.
13/ In a future post, I’ll explore how to manipulate Whisper using Python, unlocking even more potential for your projects. Stay tuned!
14/ Setting up Whisper is straightforward if you follow these steps. With the right tools and environment, you can harness this powerful speech recognition model.
15/ Want to dive deeper? Read my full article on @SoloDev.app for a detailed guide on installing and using WhisperAI.
Until next time: Be safe, be kind, be awesome! 🚀




